

تا همین اواخر، تصور بر این بود که استفاده از چت بات های هوش مصنوعی نیازمند اتصال دائمی به اینترنت و سیستمهای گرانقیمت است. خوشبختانه، امروزه ابزارهایی توسعه یافتهاند که به شما اجازه میدهند قدرت هوش مصنوعی را مستقیماً روی کامپیوتر شخصی خودتان داشته باشید. مهمترین ویژگی این روش آن است که حتی روی سیستمهای معمولی و بدون نیاز به اینترنت نیز کار میکند و حریم خصوصی شما را به طور کامل حفظ مینماید. اگر در حد نصب کردن یک برنامه ساده یا حتی یک بازی روی سیستم هم آشنایی دارید، خیالتان کاملاً راحت باشد؛ با این آموزش قدمبهقدم، خیلی سریع با چند کلیک میتوانید هوش مصنوعی شخصی خودتان را راه بیندازید.
اولاما (Ollama) چیست؟
Ollama یک ابزار رایگان و بسیار کارآمد است که به شما اجازه میدهد مدلهای هوش مصنوعی را بهسادگی روی کامپیوتر شخصی خود نصب و اجرا کنید. در واقع، اولاما مانند یک مدیر برنامه در پسزمینه سیستم شما کار میکند و تمام کارهای فنی مانند دانلود، راهاندازی و مدیریت مدلها را برایتان انجام میدهد. بهاینترتیب، شما میتوانید بدون نیاز به دانش فنی پیچیده، از قدرت هوش مصنوعی بهصورت آفلاین و با حفظ کامل حریم خصوصی لذت ببرید.
آموزش نصب اولاما
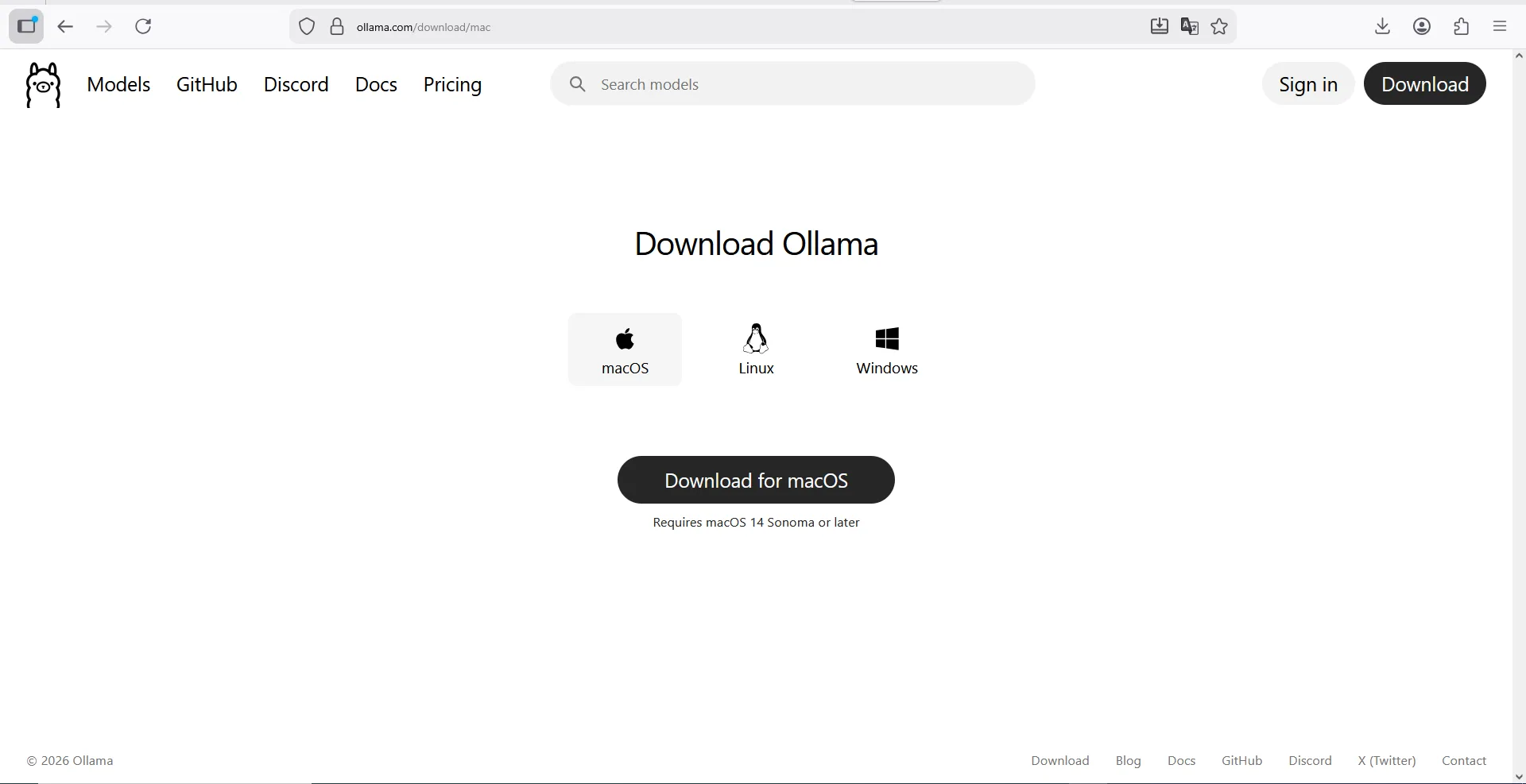
برای شروع، ابتدا باید برنامه اصلی اولاما را دانلود و نصب کنیم. این فرایند کاملاً سرراست و ساده طراحی شده است.
- به وبسایت رسمی www.ollama.com بروید؛
- در بخش Download، گزینه مناسب سیستمعامل خود (ویندوز یا مک) را برای دانلود انتخاب کنید؛
- فایل دانلود شده را اجرا و مراحل نصب را که تنها شامل یک کلیک است، دنبال کنید؛
- پس از اتمام، برنامه اولاما بهصورت خودکار برای شما باز خواهد شد.
توجه: در حال حاضر، دسترسی به وبسایت رسمی اولاما ممکن است نیازمند ابزارهای تغییر IP باشد. اولویت همیشه با دانلود مستقیم از سایت اصلی است، اما اگر با محدودیت مواجه شدید، برخی از وبسایتهای معتبر ایرانی نیز فایل نصبی آن را برای دانلود قرار دادهاند که میتوانید با جستجو، آنها را پیدا کنید.
نکته: نسخههای جدید اولاما دارای یک محیط گرافیکی کامل هستند. این یعنی دیگر نیازی به نصب یک رابط کاربری جداگانه (مانند Open WebUI) ندارید و خود برنامه اولاما بهتنهایی برای دانلود مدلها و چت کردن کافی است.
توصیه: پیش از شروع نصب اطمینان حاصل کنید که سیستمعامل شما ویندوز ۱۰ (بالاتر) یا macOS 14 Sonoma (بالاتر) باشد. همچنین، پیشنهاد میکنیم حداقل ۱۰ گیگابایت فضای خالی روی دیسک خود داشته باشید.
آموزش اضافه کردن مدلهای هوش مصنوعی به اولاما
نرمافزار اولاما بهخودیخود تنها یک بستر اجرایی است و برای شروع گفتگو، نیاز دارید تا مدلهای هوش مصنوعی موردنظر خود را به آن اضافه کنید. در ادامه، نحوه دانلود و فعالسازی این مدلها را به دو روش ساده (از طریق محیط برنامه و خط فرمان) بررسی میکنیم تا بتوانید بلافاصله استفاده از هوش مصنوعی را آغاز کنید.
روش اول: از طریق محیط گرافیکی اولاما (سادهترین راه)
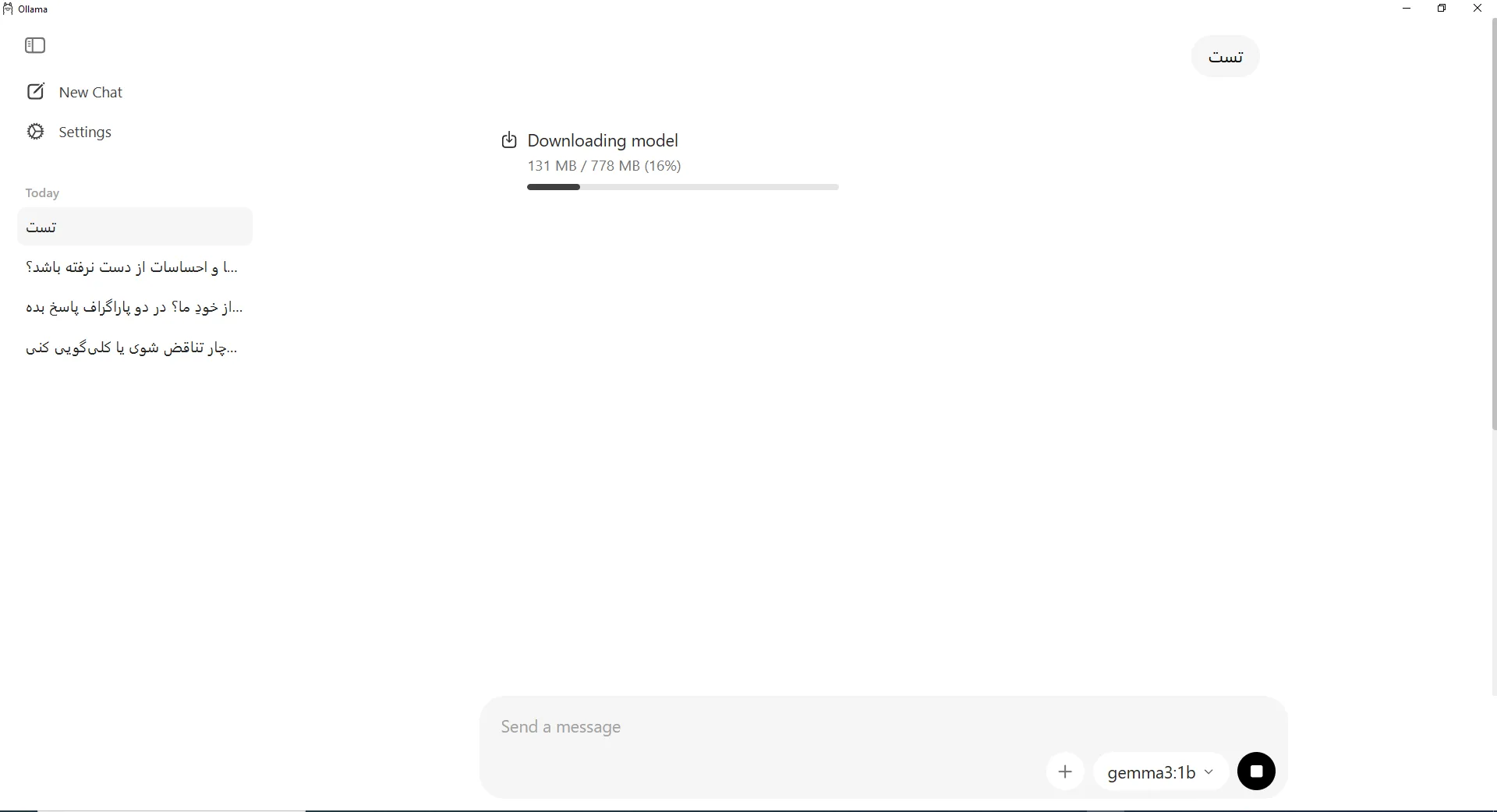
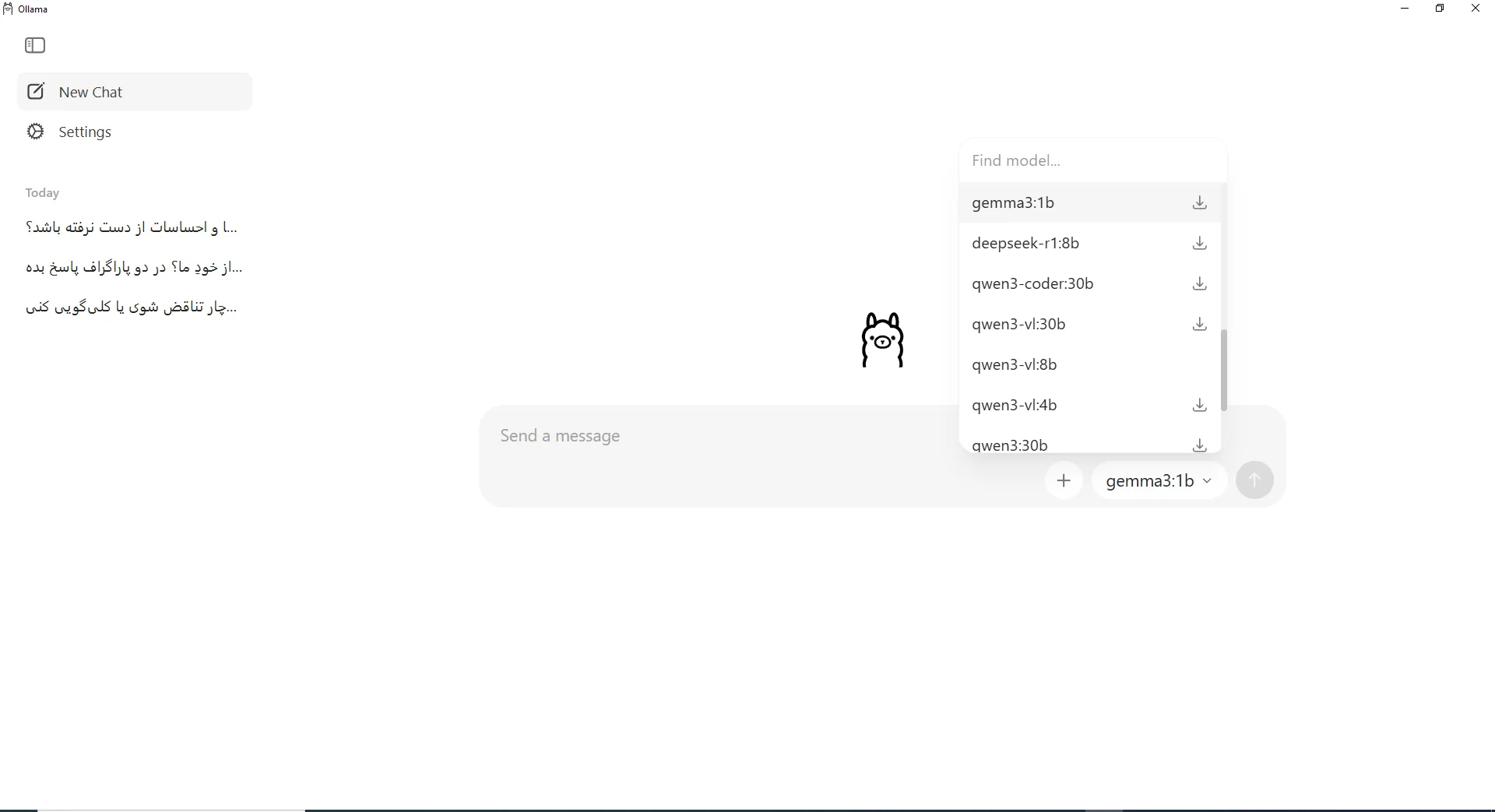
برای افزودن یک مدل جدید به کتابخانه خود، میتوانید از طریق محیط اصلی برنامه اقدام کنید. این روش به شما اجازه میدهد تا مدلها را مستقیماً از داخل رابط کاربری دانلود و فعال نمایید.
- ابتدا وارد برنامه اولاما شوید؛
- در باکس چت، از منوی کشویی، مدل موردنظر خود را انتخاب کنید؛
- پس از انتخاب مدل، یک پیام تستی ارسال کنید؛
- در این لحظه، اولاما شروع به دانلود مدل موردنظر میکند؛
- پس از تکمیل دانلود، علامت دانلود از کنار اسم مدل حذف میشود؛
- ازاینپس میتوانید با مدل انتخابی خود کار کنید.
بهاینترتیب، مدل جدید با موفقیت به کتابخانه شما اضافه شده و آماده استفاده است.
روش دوم: استفاده از ترمینال (سریع و حرفهای)
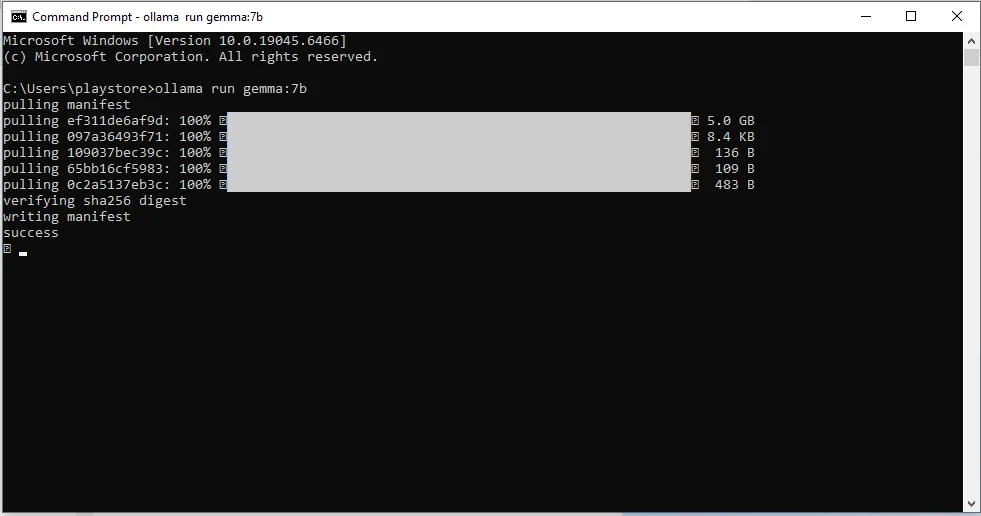
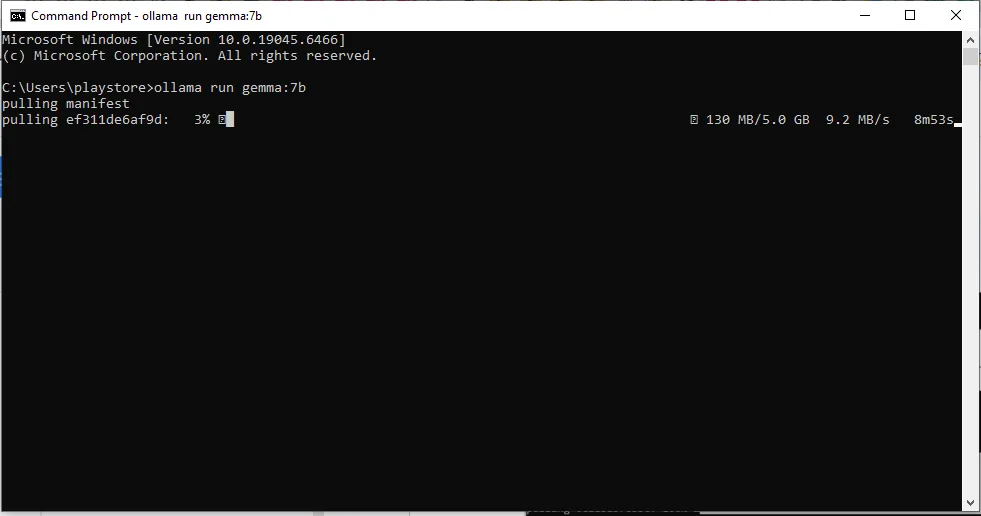
این روش در تمام سیستمعاملها (ویندوز، مک و لینوکس) یکسان عمل میکند و مدل دانلود شده بلافاصله به محیط گرافیکی شما اضافه میشود.
۱. باز کردن ترمینال
- در ویندوز: کلید Win را بزنید، در باکس سرچ، cmd را تایپ کنید و اینتر را بزنید.
- در مک (macOS): کلیدهای Command + Space را بزنید، تایپ کنید Terminal و اینتر را بزنید.
- در لینوکس: معمولاً با کلیدهای Ctrl + Alt + T ترمینال باز میشود.
۲. وارد کردن دستور دانلود
کافیست دستور زیر را تایپ کرده و کلید Enter را بزنید:
ollama run [model-name]مثال برای دانلود مدل سبک Phi-3
ollama run phi3به همین سادگی! اولاما شروع به دانلود میکند و بهمحض تمامشدن، آن مدل در فهرست برنامه گرافیکی شما ظاهر میشود و میتوانید با آن چت کنید.
کدام مدل را برای شروع دانلود کنم؟
انتخاب مدل هوش مصنوعی، دقیقاً مانند تنظیمات گرافیکی در بازیهای کامپیوتری است؛ شما باید گزینهای را انتخاب کنید که با قدرت سختافزارتان هماهنگ باشد. اصلیترین فاکتور در این انتخاب، اندازه پارامتر مدل است. پارامتر را به زبان ساده، مانند حجمِ مغزِ هوش مصنوعی در نظر بگیرید. هرچه این عدد (که با B به معنی میلیارد مشخص میشود) بزرگتر باشد، مدل دانش بیشتر و توانایی استدلال بالاتری دارد، اما در مقابل، سنگینتر شده و به منابع بیشتری (به خصوص رم) نیاز پیدا میکند.
- اگر یک سیستم خانگی یا لپتاپ معمولی با رم حدود ۴ تا ۸ گیگابایت دارید، سراغ مدلهای 1B تا 4B بروید؛ این مدلها سبک هستند و برای چت، خلاصهسازی و کارهای ساده کاملاً کافیاند.
- اگر سیستمتان متوسط است، یعنی ۱۶ تا ۳۲ گیگابایت رم یا یک GPU معمولی دارید، بهترین انتخاب مدلهای 7B تا 12B هستند؛ این بازه بهترین تعادل بین کیفیت پاسخ و مصرف منابع را دارد و برای اکثر کاربران منطقیترین گزینه است.
- در صورتی که سیستم قوی با GPU قدرتمند، VRAM بالا و حداقل ۶۴ گیگابایت رم دارید، میتوانید سراغ مدلهای 27B بروید که پاسخهای دقیقتر و پایدارتر تولید میکنند.
- مدلهای خیلی بزرگ مثل 70B یا 120B معمولاً برای اجرای لوکال طراحی نشدهاند و بیشتر مناسب سرورها و دیتاسنترها هستند، نه استفادهی خانگی.
🏆 انتخاب طلایی برای شروع؛ Gemma 3 (نسخه 4B)
اگر میخواهید فقط یک مدل دانلود کنید و خیال خودتان را راحت کنید، بدون هیچ شکی Gemma 3:4B را انتخاب کنید. این مدل برای کسانی که سیستمهای قدیمی، لپتاپهای اداری یا حتی سیستمهایی با ۴ گیگابایت رم دارند، حکم نجاتبخش را دارد.
| مشخصه فنی | توضیحات |
|---|---|
| نام مدل | Gemma 3 4B (نسخه ۴ میلیارد پارامتری) |
| توسعهدهنده | گوگل |
| عملکرد مشابه | GPT-4o mini |
| فضای رم مورد نیاز | حداقل ۳.۴ گیگابایت (اجرای عالی روی سیستمهای ۸ گیگ و قابل قبول روی ۴ گیگ) |
| فضای موردنیاز | ۳.۳ گیگابایت (سبک و کمحجم) |
| تخصصها و قابلیتها | • پشتیبانی بسیار خوب از زبان فارسی پاسخگویی به سؤالات عمومی و دانشمحور • خلاصهسازی متون طولانی • کدنویسی سبک و کمک به برنامهنویسی • قابلیت OCR (تشخیص و استخراج متن از تصاویر و اسناد) |
| مناسب برای | سیستمهای خانگی ضعیف، لپتاپهای اداری قدیمی، و کاربرانی که سرعت پاسخگویی بالا برایشان اولویت دارد. |
برای نصب این مدل، کافیست در کادر دانلود مدل در محیط برنامه، در باکس مربوط به مدلها gemma3:4b را پیدا کنید یا ترمینال را باز کرده و دستور زیر را اجرا نمایید.
ollama run gemma3:4b نکته: گوگل بهتازگی مدل Gemma 4 را معرفی کرد که در صورت دسترسی به اینترنت و امکان دانلود، پیشنهاد میکنیم از مدل gemma4:4b استفاده کنید.
خوب است بدانید: Gemma 3 نام یک خانواده از مدلهای هوش مصنوعی ساخت گوگل است که در اندازههای مختلفی (از 1B تا 27B) عرضه شدهاند. این تنوع به کاربران اجازه میدهد تا بسته به قدرت سختافزار خود، بهترین مدل را انتخاب کنند. نسخه 4B، متعادلترین و محبوبترین عضو این خانواده برای اجرا روی کامپیوترهای شخصی است.
نگاهی به سایر مدلهای محبوب
در حالی که Gemma 3 یک نقطه شروع فوقالعاده است، دنیای هوش مصنوعی پر از مدلهای متنوع با تخصصهای مختلف است. ممکن است شما به مدلی برای کدنویسی نیاز داشته باشید یا سیستمی قویتر در اختیار دارید و به دنبال هوش بیشتری هستید. در جدول زیر، چند مدل محبوب دیگر را به صورت خلاصه معرفی کردهایم تا بتوانید بهترین ابزار را برای نیاز خود پیدا کنید.
| مدل | پارامتر | حجم | مناسب برای |
|---|---|---|---|
| Llama 3.1 | 8B | ~3–4 GB | چت، کد، خلاصهسازی |
| Mistral | 7B | ~4–5 GB | چت سریع، استفاده عمومی |
| Gemma | 7B | ~6–7 GB | متن، کد، استدلال |
| Phi-3 Mini | 3.8B | ~4 GB | منطق، ریاضی، کد سبک |
| DeepSeek R1 | 8B | 4.9 GB | استدلال و کدنویسی |
| Qwen 3 | 8B | 6.1 GB | چندزبانه، ترجمه |
مطالعه بیشتر: کیفیت پاسخی که از هوش مصنوعی میگیرید، به هنر سوال پرسیدن شما بستگی دارد. برای اینکه استاد گفتگو با این ابزار شوید و بهترین نتایج را بگیرید، خواندن مطلب پرامپت نویسی چیست؟ را از دست ندهید.
جمعبندی
در نهایت، Ollama این امکان را فراهم میکند که حتی روی سیستمهای ضعیف و متوسط نیز بتوان از مدلهای هوش مصنوعی محلی استفاده کرد. با انتخاب مدلهای سبک و تنظیم درست منابع، بدون نیاز به سختافزار قدرتمند میتوان به تجربهای کاربردی و قابلقبول دست یافت.
توصیه ما این است که همیشه یک نسخه از اولاما را به همراه یکی از مدلهای سبک و کارآمد روی سیستم خود آماده داشته باشید. در شرایطی که دسترسی به شبکه محدود است یا زمانی که برای کار با اطلاعات حساس به یک محیط ایزوله نیاز دارید، داشتن یک هوش مصنوعی محلی، یک مزیت کلیدی و اطمینانبخش خواهد بود.

سؤالات متداول
۱. ارور EOF یا Connection Refused یعنی چه؟
این یعنی موتور برنامه به دلیل پر شدن حافظه رم (RAM) یا تداخل آنتیویروس بسته شده است. سیستم را ریاستارت کنید و پس از روشن شدن، سراغ مدلهای سبکتر (مثل Gemma) بروید.
۲. دانلود مدل ارور میدهد یا گیر میکند، چه کار کنم؟
احتمالاً فایل به دلیل قطعی اینترنت ناقص دانلود شده است. با دستور ollama rm [model-name] فایل خراب را حذف کنید و مجدداً دکمه دانلود را بزنید.
۳. آیا بدون کارت گرافیک قوی هم میتوانم استفاده کنم؟
بله، کاملاً. مدلهای پیشنهادی (مثل Gemma 3) طوری طراحی شدهاند که روی پردازنده اصلی (CPU) و سیستمهای معمولی هم با سرعت بالا اجرا میشوند.
۴. آیا این برنامه به اینترنت نیاز دارد و اطلاعاتم را میفرستد؟
خیر، پس از دانلود مدل، همه چیز کاملاً آفلاین کار میکند. تمام پردازشها روی سیستم خودتان انجام میشود و هیچ اطلاعاتی به خارج ارسال نمیگردد.
۵. چرا وقتی اولاما در حال کار است، سیستمم کند میشود؟
اجرای یک مدل هوش مصنوعی، مانند اجرای یک بازی سنگین، از منابع پردازنده و رم استفاده میکند. برای عملکرد بهتر، برنامههای سنگین دیگر (مانند مرورگر با تبهای زیاد) را در حین استفاده ببندید.
۶. چرا مدل از اخبار امروز یا قیمت دلار خبر ندارد؟
این مدلها به اینترنت دسترسی ندارند و دانش آنها محدود به اطلاعاتی است که تا زمان ساخته شدنشان (مثلاً سال ۲۰۲۳) وجود داشته است. آنها شبیه یک دایرهالمعارف چاپ شده عمل میکنند.
۷. چطور مدل دانلود شده را حذف کنم؟
برای حذف یک مدل و آزاد کردن فضا، باید از ترمینال (CMD) استفاده کنید. کافیست دستور ollama rm [نام-مدل] را وارد نمایید. برای مثال، برای حذف مدل phi3، دستور ollama rm phi3 را اجرا کنید.
۸. چرا پاسخ اولین سوال من خیلی طول میکشد، اما جوابهای بعدی سریع است؟
وقتی اولین سوال را میپرسید، اولاما باید تمام فایل چند گیگابایتی مدل را از روی دیسک به حافظه رم (و VRAM کارت گرافیک) منتقل کند. این کار زمانبر است، اما به محض اینکه مدل بارگذاری شد، برای سوالات بعدی در حافظه باقی میماند و پاسخها تقریباً آنی خواهند بود.
۹. آیا اولاما مکالمات قبلی من را به خاطر میآورد؟
بله، اما با یک محدودیت. هر مدل یک حافظه کوتاهمدت دارد. تا زمانی که مکالمه شما در محدوده این پنجره باشد (مثلاً ۲۰۴۸ کلمه)، مدل همه چیز را به یاد میآورد. اما اگر گفتگو خیلی طولانی شود، اوایل آن را فراموش میکند تا بتواند روی اطلاعات جدیدتر تمرکز کند.
۱۰. در نام مدلها، حرف B (مثل 4B) به چه معناست؟
B مخفف Billion (میلیارد) و نشاندهنده تعداد «پارامترهای» مدل است. هرچه این عدد بزرگتر باشد، مدل معمولاً هوشمندتر اما سنگینتر است و به رم بیشتری نیاز دارد.
۱۱. وقتی یک مدل هوش مصنوعی را دانلود میکنم، کدام نسخه مدل دانلود میشود؟
اولاما به صورت خودکار بهینهترین نسخه فشردهشده (Quantized 4-bit) را برای شما دانلود میکند. این کار باعث میشود مدل روی سیستمهای معمولی با رم کمتر، روان و سریع اجرا شود.
۱۲. تفاوت نسخههای q4، q8 و … در چیست؟
اینها سطح فشردهسازی (Quantization) مدل را نشان میدهند. هرچه عدد q کمتر باشد (مثل q4)، مدل کمحجمتر و سریعتر است، اما دقت آن ممکن است کمی کاهش یابد. نسخه q4 بهترین تعادل را دارد.
۱۳. چطور بفهمم یک مدل برای سیستم من مناسب است؟
قانون کلی این است که مقدار رم سیستم شما باید کمی بیشتر از حجم فشردهشده مدل باشد. برای مثال، یک مدل 7B (با حجم حدود ۵ گیگ) برای اجرا روی سیستمی با ۸ گیگابایت رم مناسب است.
۱۴. چطور تمام مدلهایی که نصب کردهام را ببینم؟
ترمینال (CMD) را باز کرده و دستور ollama list را اجرا کنید. این دستور، لیستی از تمام مدلهای نصب شده روی سیستم شما را به همراه حجم آنها نمایش میدهد.
۱۵. چطور اطلاعات یک مدل خاص (مثل نسخه فشردهسازی) را ببینم؟
برای دیدن جزئیات فنی یک مدل، در ترمینال دستور ollama show [نام-مدل] را بزنید. این دستور «شناسنامه» مدل را نشان میدهد و میتوانید بفهمید دقیقاً کدام نسخه را دارید.
۱۶. چطور مدلهایی که در لیست برنامه نیستند را نصب کنم؟
لیست برنامه فقط یک پیشنهاد است. شما میتوانید نام هر مدلی از کتابخانه اولاما جستجو کنید یا از دستور ollama run [model-name] در ترمینال استفاده نمایید.
۱۷. با اینترنت نامطمئن ایران، آیا راهی برای دانلود مدلهای حجیم با قابلیت Resume Support هست؟
بله، اما نه با دستور مستقیم اولاما. بهترین راه این است که با یک نرمافزار مدیریت دانلود (Download Manager)، فایل مدل (.gguf) را از سایتی مثل Hugging Face دانلود کنید. سپس آن فایل را به اولاما اضافه نمایید.
با تشکر از شهرام شهبازی



















نظر بدهید
نشانی ایمیل شما منتشر نخواهد شد.