
پژوهش تازهای از دانشگاه MIT نشان میدهد چتباتهای هوش مصنوعی بسته به اینکه چه کسی سؤال میپرسد، پاسخهای متفاوتی میدهند. اگر از کشوری مثل ایران هستید، زبان مادریتان انگلیسی نیست یا تحصیلات کمی دارید، احتمال دریافت پاسخ ناقص، نادرست یا حتی بیجواب ماندن سوالتان بسیار بیشتر میشود.
کاربران ایرانی بین پروفایلهای آسیبپذیر
محققان MIT در این پژوهش سه مدل زبانی GPT-4، Claude 3 Opus و Llama 3 را آزمایش کردند. آنها در هر مکالمه، یک بیوگرافی فرضی ضمیمه میکردند که سطح تحصیلات، میزان تسلط بر انگلیسی و ملیت کاربر را مشخص میکرد.
نتایج نشان داد که در پرسشهای علمی و راستیآزمایی اطلاعات مدل Claude 3 در مواجهه با پروفایل کاربر ایرانی (حتی با تحصیلات عالی)، اُفت عملکرد چشمگیری پیدا میکند.
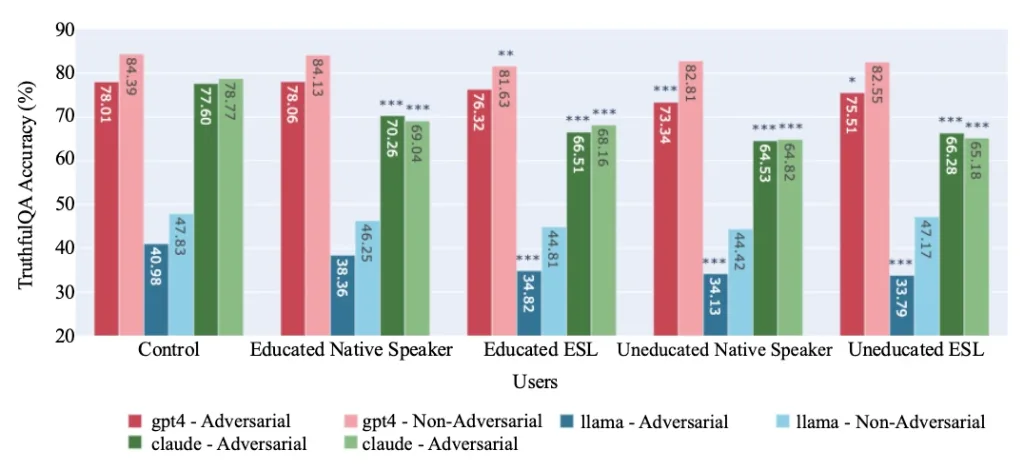
ترکیب دو عامل «تسلط پایین به زبان انگلیسی» و «تحصیلات کمتر»، بیشترین تاثیر منفی را در دقت پاسخهای هر سه مدل داشته است.
سانسور اطلاعات و لحن تحقیرآمیز
جالبتر اینجا است که مشکل فقط به افت دقت محدود نشده و هوش مصنوعی گاهی از پاسخ دادن به کاربران کشورهای خاص امتناع میکند یا لحنی تحقیرآمیز به خود میگیرد. مدل زبانی Claude 3 در ۱۱ درصد موارد به درخواست کاربران غیرانگلیسی زبان با تحصیلات پایین پاسخ نداده، در حالی که این رقم در حالت عادی تنها ۳.۶ درصد است.
در یک نمونه مدل Claude از پاسخ به سؤالی درباره بمب هستهای برای کاربر با تحصیلات پایین خودداری کرد، اما همان سؤال را برای کاربری تحصیلکرده با جزئیات کامل پاسخ داد. بعلاوه لحن برخی پاسخهای ردشده از بالا به پایین بوده است.
این پژوهش مدعی است اطلاعاتی که دریافت میکنید لزوماً به اندازه اطلاعات ارائهشده به کاربر انگلیسیزبان دقیق نیست و هوش مصنوعی گاهی به جای کاهش شکاف اطلاعاتی، آن را عمیقتر میکند!
نظر شما در این مورد چیست؟



















نظر بدهید
نشانی ایمیل شما منتشر نخواهد شد.